この記事はトラストバンクAdvent Calender 2023の12日目の記事です。
お久しぶりになってしまいました。フロントエンドエンジニアの田口です。
しばらくSentryのお世話がおざなりになってしまっていましたが、最近またフィルタリングの設定を加えました。
そのときにSentryと直接やり取りしたり、ドキュメントを見直したりして自分の勘違いに気づくことができましたので、共有したいと思います。
今回やりたかったこと
今回追加したかったフィルタリングは、サービスの推奨環境外の古いモバイルOSを検知対象からは外すというものです。
ふるさとチョイスでは携帯端末の推奨環境を以下のように定めています。
iPhone iOS14以降 Safari 最新版 Android 9.0以降 Google Chrome 最新版
この推奨環境未満のバージョン、つまりiOS 13やAndroid 8といった古いOSバージョンの端末で発生したクライアントエラーについては、 SentryのIssuesに追加しないようにします。
これの理由としてはSentryのクォータの節約が主です。
フィルタリングの仕込み
BeforeSendの使用
以前Sentryのフィルタリングについて書いた際、beforeSendについて記載しました。
ふるさとチョイスで使用しているSentryのプランは変わっていませんので、今回もbeforeSendでフィルタリングします。
beforeSendの引数であるeventの持っている情報が重要そうです。
Sentryの画面でeventの中身を推測してみる
Sentryの管理画面では全てのエラーイベントの発生した環境が確認できます。
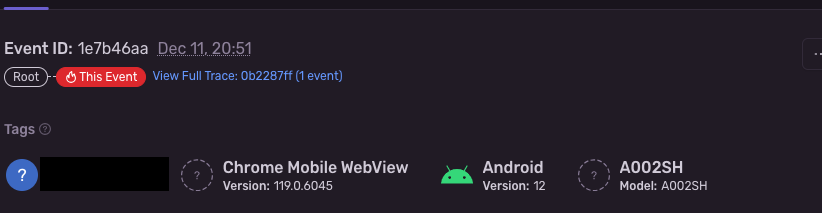
OSのタイプだけでなく、バージョンまで分かります。
Sentryの管理画面ではエラーイベントをJSONとして拾うこともできます。

JSONの内容は割愛しますが、このJSONにもOSなどの情報が同じように載っています。
Event Payload
恐らく上に書いたような内容がbeforeSendのeventに入ってくるはずですが、SentryのAPIドキュメントを更に漁ってみます。
これですね。
OSに関する情報はこの中のContexts Interfaceで実装されています。
JSONの中身の紹介は割愛しましたが、そこにもcontextsのキーと値が入っています。
いざ実装
event.contextsからOSの情報まで辿り着けそうだったので、最初は以下の実装を試しました。
const checkLegacyOS = event => { const IOS_VERSION = 14; const ANDROID_VERSION = 9; const os = event.contexts.os.name; const { version } = event.contexts.os; return ((os === 'iOS' && Number(version.split('.')[0]) < IOS_VERSION) || (os === 'Android' && Number(version.split('.')[0] < ANDROID_VERSION))); };
しかしなんということでしょう、os.nameもos.versionも存在していません。そもそもOSなどの情報がeventに一切ありません。
試しに発生させたエラーはSentryで検知されており、しっかり管理画面から見ることができます。そしてOSの情報も入っている……
一時的に混乱に陥りました。
解決
とりあえずSentryのチャットとメールでやり取りをしつつ、色々調べたところ、普通にドキュメントに書いてありました。
In events reported from a JS web frontend, the SDK typically reports no OS context.
こんなこと書いてあったけどマジ?とSentryのフランシスにメールで聞いてみたところ、
「あ〜そうそう!その通り!OS ContextsはbeforeSendじゃ拾えないよ。SentryにPOSTするときのヘッダーでユーザーエージェントとってるからそれとeventをくっつけてるんだ。」
「だからbeforeSendでフィルタリングするときに使うなら、ユーザーエージェントからtagsに情報入れるとできるよ。」
と教えてくれました。ありがとうフランシス。
tagsはここに記載がありますが、要はeventに任意のパラメータを追加できる、みたいな考え方で良いと思います。
event.tagsでオブジェクト形式で拾えます。公式のスニペットを貼っておきます。
{ "tags": { "ios_version": "4.0", "context": "production" } }
Event Payloads | Sentry Developer Documentation
tagsの付与はinitialScopeで行うのが良いとフランシスが言ってました。
ということで、最終的にこんな感じになりました。
// 古いモバイルOSか(trueなら除外) const checkLegacyOS = event => { const IOS_VERSION = 14; const ANDROID_VERSION = 9; const mobileType = event.tags?.mobileType; const version = event.tags?.majorVersion ? Number(event.tags.majorVersion) : null; if (!mobileType || version === null) return false; if (mobileType === 'iPhone' || mobileType === 'iPad') return version < IOS_VERSION; if (mobileType === 'Android') return version < ANDROID_VERSION; return false; }; const getMobileTag = () => { const ua = navigator.userAgent.toLowerCase(); const isIphone = ua.includes('iphone'); const isIpad = ua.includes('ipad') || (ua.includes('macintosh') && 'ontouchend' in document); const isAndroid = ua.includes('android'); if (isIphone) { const type = 'iPhone'; return createTagObject(type, ua, /iphone os [\d_]+/); } if (isIpad) { const type = 'iPad'; if (ua.includes('ipad')) return createTagObject(type, ua, /cpu os [\d_]+/); return createTagObject(type, ua, /version\/[\d.]+/); } if (isAndroid) { const type = 'Android'; return createTagObject(type, ua, /android [\d.]+/); } }; // SentryのTag情報を作成 const createTagObject = (mobileType, ua, matcher) => { const [osDetail] = ua.match(matcher) ?? ['unknown']; const [majorVersion] = osDetail.match(/\d+/) ?? ['unknown']; return { mobileType, osDetail, majorVersion }; };
Sentry.init()はこんな感じです。(だいぶ省略してます)
Sentry.init({ integrations: [new Sentry.BrowserTracing()], initialScope(scope) { const tags = getMobileTag(); if (tags) scope.setTags(tags); }, beforeSend(event) { // 色々フィルタリング } }
まとめ
Sentryのフィルタリングについてまた一つ理解しました。
特にtagsの使用は応用範囲が広く感じましたので、みなさんもぜひ活用してみてください。
最後にいつもの!
トラストバンクではフロントエンドエンジニアの仲間を大募集しております。
この投稿以外にも他の記事で興味を持ったらぜひ一度お話ししてみませんか?